
티스토리 뷰
[논문리뷰] MobileNet V2 설명, pytorch 코드(Inverted Residuals and Linear Bottlenecks)
minimin2 2020. 3. 2. 21:06안녕하세요, 오늘은 google에서 작성한 MobileNet의 두 번째 버전입니다.
정식 이름은 MobileNetV2: Inverted Residuals and Linear Bottlenecks로 기존의 MobileNet에서 cnn구조를
약간 더 수정하여 파라미터 수와 연산량을 더욱 줄인 네트워크입니다.
논문링크: https://arxiv.org/abs/1801.04381
MobileNetV1 리뷰: https://minimin2.tistory.com/42
우선 논문에 제시된 아래 cnn 구조를 먼저 살펴보겠습니다.
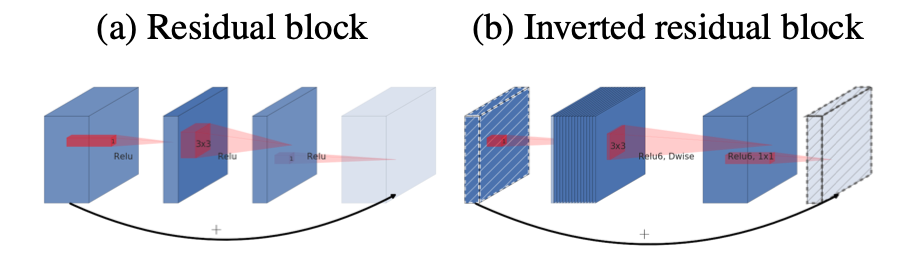
두 구조의 block내부는 모두 지난 포스팅에서 설명드린 depthwise separable convolution입니다.
(a)는 일반적인 resnet 구조에서 사용하는 residual 구조입니다. block안에서는 적은 channel수로 convolution 하는 것이 특징입니다.
(b)는 (a)와 다르게 block안에서의 channel이 더 크고 밖에서는 축소하는 형식입니다. 그래서 Inverted residual block이라는 이름이 붙은 것 같습니다.
전체적인 network 구조는 아래와 같습니다.

위에서 bottleneck은 위 (b)의 구조라고 생각하시면 됩니다.
t: block내부에서 팽창시킬 배수 (block내부 채널 수 = t*c)
c: 채널 수
n: blottleneck의 반복수
s: stride (값이 2인 경우, 최초 1회만 stride를 주어 h, w를 절반으로 줄임, residual구조는 사용하지 않음)
내부 구조를 다시 한번 살펴보면 아래 그림과 같습니다.
stride가 1일 때에는, residual network를 그대로 사용하여 add 해 주었고,
stride가 2일 때에는, residual network 없이 convolution의 stride를 2로 주어 size를 절반으로 줄입니다.
또 다른 특징으로는 ReLU6를 사용하였다는 것인데, 이는 기존 ReLU의 x>0인 구간에서 x, x>6인 구간은 6으로 하는 함수입니다.
이를 사용한 이유로는 low precision을 사용하기 때문이라고 합니다.
(원문: We use ReLU6 as the non-linearity because of its robustness when used with low-precision computation.)

종합해보면
첫 번째로 모든 convolution을 MobileNet의 depthwise separable convolution으로 대체하였고,
두 번째로 연산량과 파라미터량을 줄이기 위해 전체적으로 convolution의 channel수를 줄이고, block의 내부에서만 channel수를 증가시켰습니다.
마지막으로 기존의 ReLU대신 ReLU6를 사용하였습니다.
[Result]
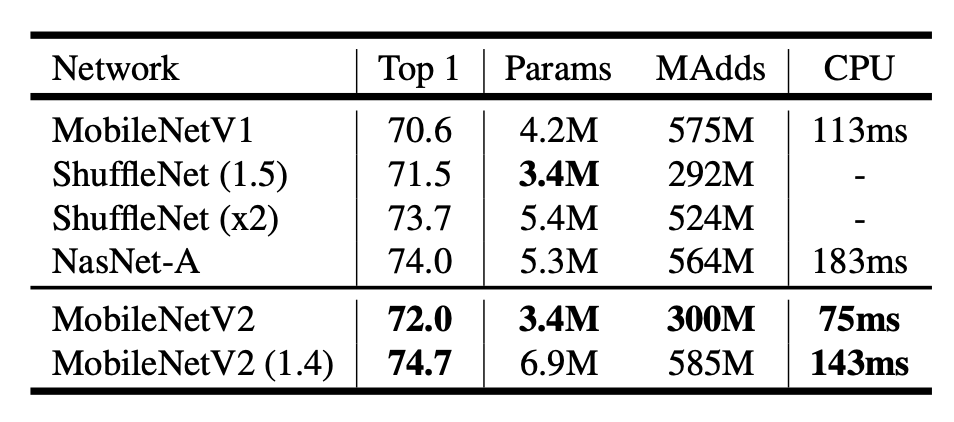
아래 표와 같이 MobileNetV2는 Params와 MAdds, 연산속도를 획기적으로 줄이면서, 기존의 MobileNet, ShuffleNet보다 더 좋은 성능을 보여줍니다. 이 뿐만 아니라 detection, segmentation에서도 적은 파라미터량으로 우수한 성능을 보입니다.
(더 많은 실험 결과는 논문에 있습니다.)
github 소스코드: https://github.com/jmjeon94/MobileNet-Pytorch/blob/master/MobileNetV2.py
'ML | DL' 카테고리의 다른 글
| [딥러닝] Tensorflow에서 커스텀 데이터로더 만들기(Custom Dataloader) (0) | 2020.08.29 |
|---|---|
| [딥러닝] 이미지 평가방법(Confusion matrix, Recall, Precision, Accuracy, F1 Score) (0) | 2020.05.18 |
| [논문리뷰] MobileNet V1 설명, pytorch 코드(depthwise separable convolution) (0) | 2020.02.27 |
| [논문리뷰] CAM(Class Activation Map-Learning Deep Features for Discriminative Localization) (3) | 2019.12.05 |
| [딥러닝]tensorflow로 CNN구현하기(MNIST) (0) | 2019.02.14 |
- Total
- Today
- Yesterday