
티스토리 뷰
[논문리뷰] CAM(Class Activation Map-Learning Deep Features for Discriminative Localization)
minimin2 2019. 12. 5. 23:32안녕하세요, 딥러닝 관련 논문을 읽으며 나중에 공부한 내용을 상기하고자 논문리뷰 포스팅을 시작합니다.
단순 공부 목적으로 틀린 부분이 있으면 지적해주시면 감사하겠습니다.
첫 논문은 Learning Deep Features for Discriminative localization 이라는 논문입니다.
[Introduction]
기존 CNN의 모델은 classification 을 이미지 내에서 어떤 특징(feature)를 보고 판단하는지 알 수가 없었습니다.
하지만 출력의 결과를 시각화하여 실제 모델이 이미지의 어떤 부분을 보고 분류하는지 알 수 있게 하였습니다.
이를 Class Activation Map이라고 하며, 줄여서 CAM라고 부릅니다.
[모델]
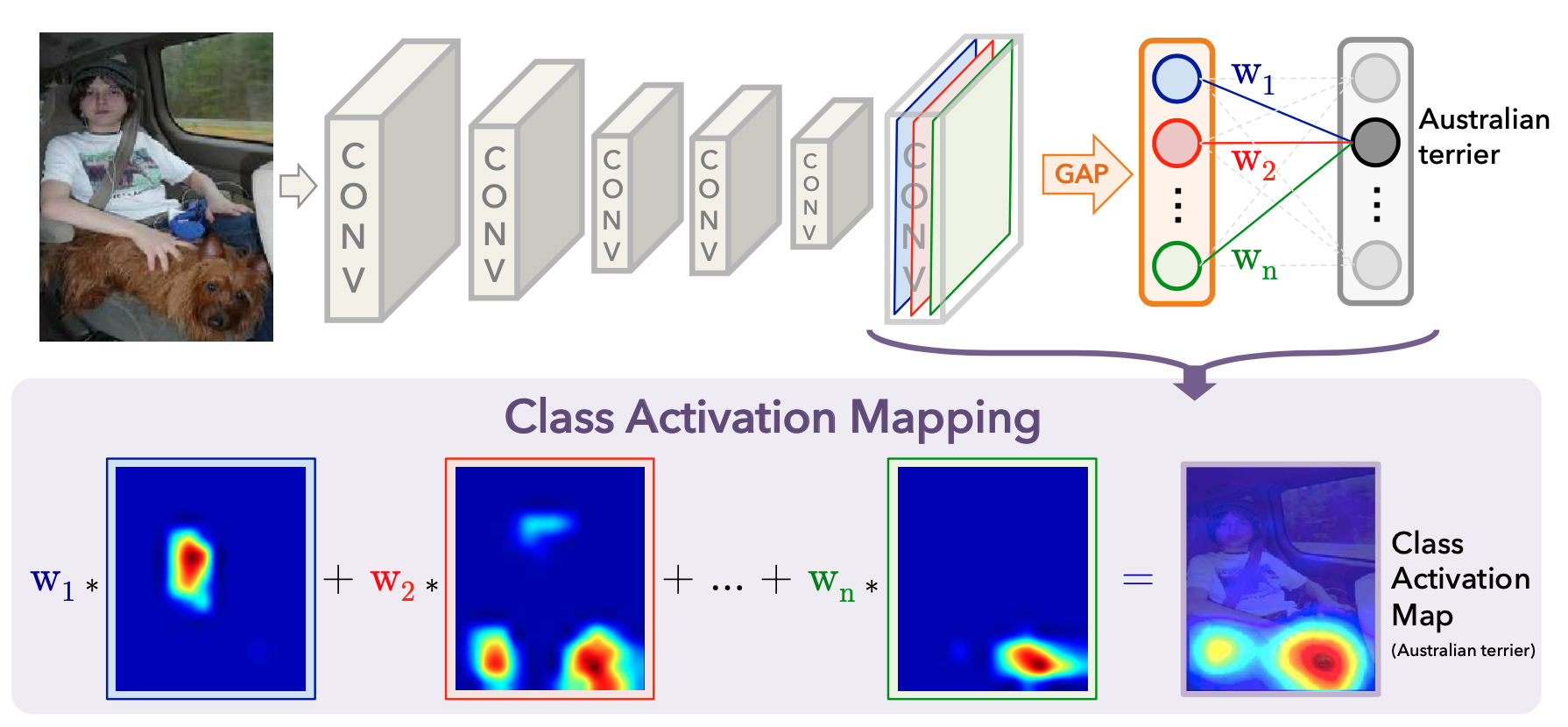
기존 일반적인 모델에서는 마지막 feature map을 flatten하여 1차원 벡터로 만든 뒤 이를 Fully Connected Netowork를 통과하여 softmax로 classification을 하였습니다.
하지만 flatten을 거치면서 feature map의 인접한 픽셀간의 spatial한 정보를 잃게 되고, 또한 이로인해 FC의 input수가 매우 많아지기 때문(n_Ch*H*W)에, 파라미터의 수가 급증하는 문제가 있었습니다.
이를 해결하기 위해 해당 논문에서는 기존 flatten방식과 달리 GAP(Global Average Pooling)방식을 적용합니다.
GAP이란 기존 pooling방식 중 하나로, 각 채널의 평균값으로 pooling하는 기법입니다. [n_CH, H, W] -> [n_CH, 1, 1]
위의 그림에서와 같이 각 채널에서 색 별로 average 하나의 값만을 가져오게 됩니다. 그 이후에 FC를 적용하는데 이때의
weight값이 CAM을 만드는 w1, w2, w3, ... 값이 됩니다.
(이때의 FC는 input size가 단지 n_Ch이므로 기존 n_Ch*H*W에 비해 매우 적어짐을 알 수 있습니다.)
FC의 weight는 [n_Ch, n_classes]의 크기를 갖는 matrix인데, FC matrix의 클래스index 열 벡터가 각각 w1, w2, wn,...가 됩니다. (*n_classes는 분류하려는 객체의 수)
이 weight들을 마지막 feature map에 각각 곱한 후에 더해주면 CAM이 됩니다.
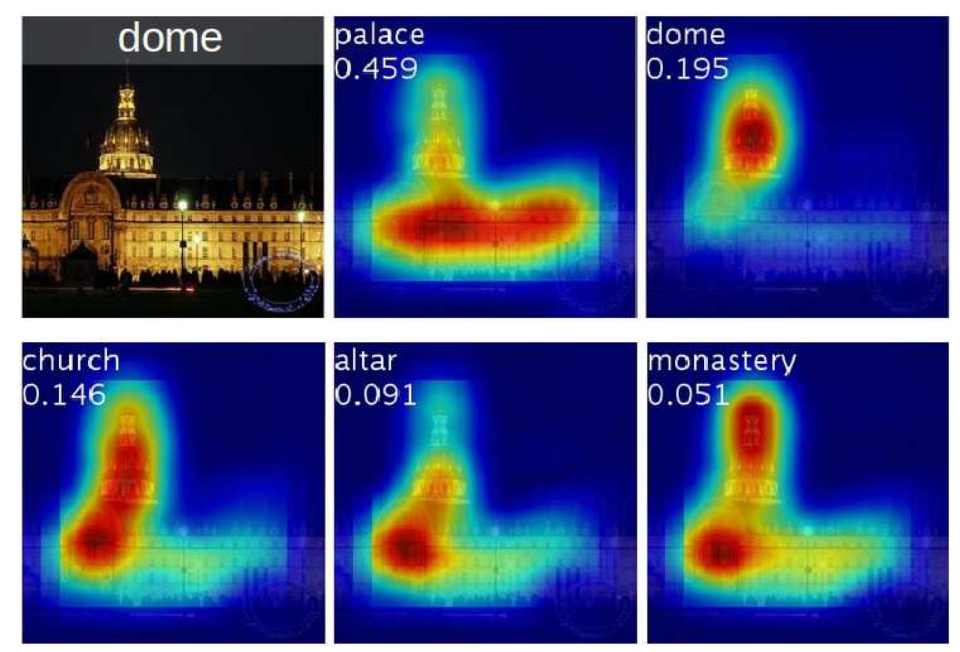
위 그림은 왼쪽 상단의 이미지를 input으로 넣었을 때 Top-5 class의 CAM인데, 각각의 class가 이미지에서 어디를 보고 판단하는지 알 수 있습니다. (실제로 가장 높은 확률로 분류한 것은 palace, P=0.459 이지만 다섯가지 모두 틀렸다고 하긴 어렵다.)
[결론]
CAM기법은 기존 CNN모델에서 모델이 이미지에서 어딜보고 분류하는지 시각화할 수 있게 하였습니다.
또한 위치정보에 대한 annotation없이도 객체의 위치를 어느정도 localization할 수 있기 때문에 큰 의미가 있는 것 같습니다.
마지막으로, CAM을 확인하여 모델이 잘못 분류하고 있는 이미지 데이터에 대한 분석도 가능할 것으로 보입니다.
'ML | DL' 카테고리의 다른 글
| [논문리뷰] MobileNet V2 설명, pytorch 코드(Inverted Residuals and Linear Bottlenecks) (3) | 2020.03.02 |
|---|---|
| [논문리뷰] MobileNet V1 설명, pytorch 코드(depthwise separable convolution) (0) | 2020.02.27 |
| [딥러닝]tensorflow로 CNN구현하기(MNIST) (0) | 2019.02.14 |
| [딥러닝]tensorflow로 손글씨 숫자 인식하기(MNIST) (0) | 2019.01.31 |
| [딥러닝]tensorflow로 로지스틱 회귀 구현하기(Logistic Regression) (0) | 2019.01.30 |
- Total
- Today
- Yesterday