
[ML] Pycaret으로 ML모델 쉽게 만들기
Pycaret이란?
pycaret이란 AutoML을 하게 해주는 파이썬 라이브러리입니다. scikit-learn 패키지를 기반으로 하고 있으며 Classification, Regression, Clustering, Anomaly Detection 등등 다양한 모델을 지원합니다. 공식문서에 설명이 매우 잘 되어있고, 몇 줄의 코드로 쉽게 구현이 가능하여 유용하게 사용할 수 있을 것 같습니다.
1. 데이터셋 준비, setup
pycaret에서 제공하는 get_data 함수로 juice 데이터를 불러오겠습니다. 데이터를 불러오면 자동으로 .head() 를 실행해 5개의 row를 출력합니다.
from pycaret.datasets import get_data
dataset = get_data('juice')
이제 setup()이라는 강력한 함수로 추후에 필요한 모든 환경을 initialize해주는데요, 이때 사용되는 파라미터가 굉장히 다양하니 공식문서를 참고하면 도움이 될 것 같습니다. 일단은 간략하게 생성해 보겠습니다.
feature column과 label column이 같이 있는 pandas dataframe에서 target이라는 파라미터에 label column 이름을 입력합니다.
from pycaret.classification import *
setup_clf = setup(data=dataset, target='Purchase')그럼 왼쪽과 같이 모든 column에 대한 자료형이 나오는데요, 확인 하고 엔터를 쳐주면 자동으로 setup으로 설정된 모든 세팅값이 오른쪽 화면처럼 출력됩니다.
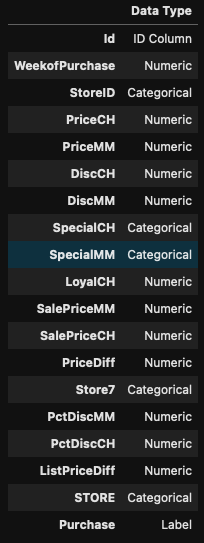

2. 모델 생성
create_model()
create_model() 함수로 특정 ML을 만들고 학습할 수 있는데요, 지원하는 ML과 파라미터로 넣어야 하는 이름은 다음과 같습니다.

가볍게 예시로 random forest를 생성해 보겠습니다. Random Forest Classifier는 rf라는 ID를 사용하네요. fold는 데이터셋을 5개로 나누어 cross validation하는 것을 의미합니다. create_model() 함수는 선언과 동시에 바로 학습하고 결과까지 띄워줍니다.
rf = create_model('rf', fold=5)
fold를 5로 했으니 5개의 학습 결과와 그 평균값으로 결과를 보여줍니다.
compare_models()
위에서 하나의 ML 모델을 생성해서 학습하는 방법을 알아봤으니, pycaret의 강력한 기능인 모든 ML기법을 활용해서 비교하는 방법을 알아보겠습니다.
compare_models()라는 함수로 지원하는 대부분의 ML모델들을 자동으로 학습하여 결과를 띄워줍니다. 이때 파라미터로 원하는 metric으로 정렬을 할 수 있고, 사용을 원하는 모델의 개수를 지정해 줄 수 있습니다.
top5 = compare_models(sort='Accuracy', n_select=5)
각 metric별로 가장 성능이 좋은 위치에 노란색으로 highlighting이 되어서 출력이 됩니다. 위에 열거된 모델 들 중 Accuracy 기준으로 성능이 좋은 5개의 모델만 top5 변수에 입력하고 이를 출력해보면 아래처럼 선택된 5개의 모델을 확인할 수 있습니다.

3. 모델 Tuning, Blending
Model Tuning
그럼 이제 위에서 선택된 5개의 모델을 tuning해보겠습니다. pycaret에서 지원하는 tune_model() 함수를 사용합니다. 기본 파라미터로 튜닝할 모델 변수를 입력하면 됩니다. 이외에도 다양한 파라미터가 있지만 기본 옵션으로 진행해보겠습니다.
tuned_top5 = [tune_model(i) for i in top5]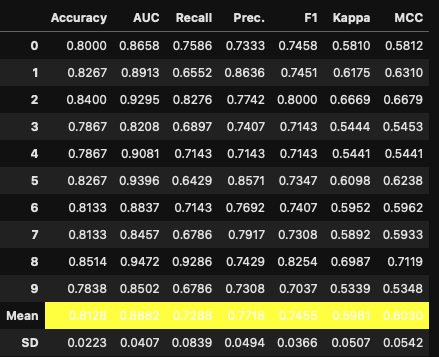
tune_model()함수도 실행과 동시에 진행되며, 출력 결과를 띄워줍니다. 기본값으로 fold가 10이므로 10개의 결과와 평균 결과가 출력됩니다. 튜닝 전에 진행했던 top5와 tuned_top5를 비교해보면 모델 안의 파라미터 값들이 변경된 것을 확인할 수 있습니다.

Blending
이제 위 5개의 모델을 혼합한 모델을 생성합니다. blend_models() 함수를 사용하여 위에서 튜닝한 tuned_top5 변수를 입력합니다.
blender_top5 = blend_models(estimator_list=tuned_top5)
잘 안보이지만 Accuracy의 Mean값이 0.8169로 위의 tuned_top5의 결과(0.8128)보다 값이 아주 조금 좋아졌습니다.
4. Prediction
학습한 최종 모델로 Prediction 하는 방법을 알아보겠습니다. 우선 지금까지는 setup에 넣었던 데이터가 KFold 방식으로 train/valid 로 나누어 학습했었습니다. finalize_model()함수를 통해 전체 데이터로 마지막 학습을 진행합니다.
이후에 predict_mdodel() 함수의 파라미터로 학습된 모델 변수, 테스트할 pandas dataframe을 각각 입력해주면 됩니다. 아래 코드에서는 테스트 데이터로 dataset의 마지막 100개의 데이터를 사용하겠습니다.
final_model = finalize_model(blender_top5)
prediction = predict_model(final_model, data=dataset.iloc[-100:])아래는 prediction 의 출력입니다. prediction은 test data의 데이터 프레임 형태를 그대로 가져가며 마지막에에 Label 이라는 column이 생기고, 여기에 모델이 예측한 결과가 추가됩니다.

5. 평가
마지막으로 모델을 평가할 차례입니다. check_metric을 import 해주고, gt와 prediction을 각각 입력하고, 확인하고 싶은 metric을 입력해주면 결과값이 출력됩니다.
from pycaret.utils import check_metric
check_metric(prediction['Purchase'], prediction['Label'], metric = 'Accuracy')
# 0.79전체 코드
위에서 사용한 코드들을 다시 정리해서 한 눈에 확인해보겠습니다. 단 몇줄만으로 대부분의 ML 방법으로 학습, 비교하고 결과까지 확인 할 수 있습니다. kaggle같은 데이터 대회에서 유용하게 사용할 수 있을 것 같습니다.
from pycaret.datasets import get_data
from pycaret.classification import *
from pycaret.utils import check_metric
# dataset 생성
dataset = get_data('juice')
# setup으로 init
clf = setup(data=dataset, target='Purchase')
# ML 모델 성능 비교
top5 = compare_models(sort='Accuracy', n_select=5)
# 모델 튜닝, blending
tuned_top5 = [tune_model(i) for i in top5]
blender_top5 = blend_models(estimator_list=tuned_top5)
# 모델 최종 확정, 전체 데이터 학습
final_model = finalize_model(blender_top5)
# 테스트셋 predict
prediction = predict_model(final_model, data=dataset.iloc[-100:])
# metric 확인
check_metric(prediction['Purchase'], prediction['Label'], metric = 'Accuracy')