
[딥러닝] Mixed Precision 사용하기(tensorflow 설명)
개요
mixed precision은 모델 학습시 FP16, FP32 부동 소수점 유형을 상황에 따라 유연하게 사용하여 학습을 더 빠르게 실행하고 메모리를 적게 사용하는 방법이다. Forwad, Backward Propagation은 모두 FP16으로 연산하고, weight를 업데이트 할 때에는 다시 FP32로 변환하여 계산한다.

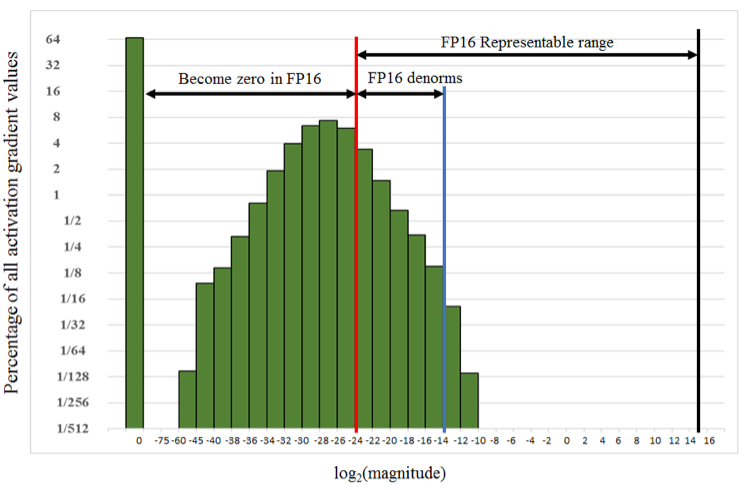
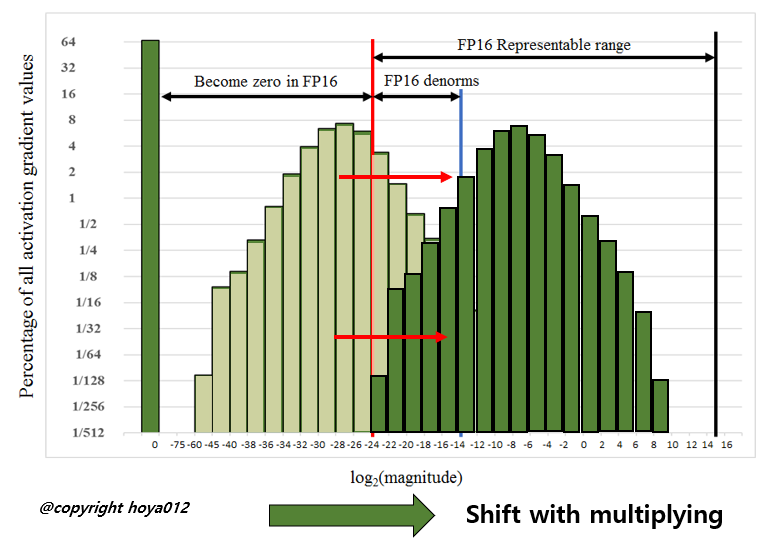
단, FP16의 경우, 매우 낮은 수는 표현할 수 없어 모두 0이 된다. 이를 방지하기 위해 특정 값을 곱하여(scaling하여) loss, gradients 계산하고 weight를 업데이트한다. 이때 FP16 범위를 벗어나는 underflow, overflow가발생하지 않게 적정한 값으로 scaling 해줘야 하는데, tensorflow에서 dynamic scaling 값을 알아서 계산해준다.
장점
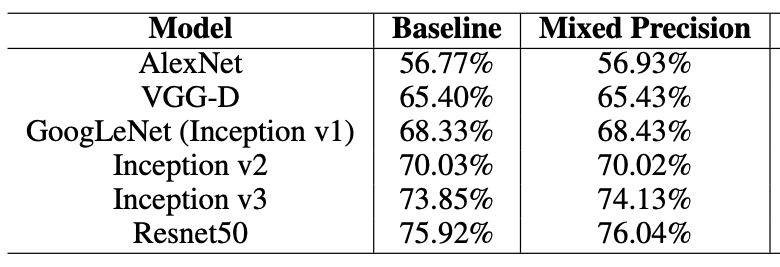
- 기존 FP32로 학습한 것 대비, 정확도의 손실이 없거나 오히려 향상됨
- 메모리가 절반으로 줄어들어, 배치 사이즈를 늘리거나, 더 큰 모델을 학습할 수 있음
Tensorflow에서 지원
- NVIDIA의 GPU 페이지 에서 자신의 GPU를 찾아 Compute Capability가 7.0 이상이면 Tensor Cores 하드웨어로 인해 mixed precision의 큰 이점을 볼 수 있다.
- Tensorflow 버전 2.1.0 이상에서 지원한다.
- 기존 소스에서 몇 줄만 수정하면 쉽게 사용할 수 있다.
소스코드
tensorflow에서 제공하는 코드는 다음과 같이 동작한다.
- 모델의 모든 global layer들을 float16으로 정의한다.
mixed_precision을 import 한 후에
policy변수를 만들고 적용한다. 이때, loss_scale 파라미터로 값을 지정할 수 있지만, default로 auto scaling 해주는 tf.mixed_precision.experimental.DynamicLossScale을 사용한다.from tensorflow.keras.mixed_precision import experimental as mixed_precision policy = mixed_precision.Policy('mixed_float16') mixed_precision.set_policy(policy)
- 모델 생성 시 마지막 output layer의 dtype은 float32로 지정해준다.
inputs = ... outputs = tf.keras.layers.Activation('sigmoid', dtype='float32')(inputs) model = tf.keras.models.Model(inputs, outputs)
- optimizer를 dynamic scale 해주는 mixed precision으로 wrapping해준다.
loss_object = ... optimizer = keras.optimizers.Adam() optimizer = mixed_precision.LossScaleOptimizer(optimizer, loss_scale='dynamic')
- loss 변수를 scaling 하여 scaled loss, scaled gradients 값을 구하고,
scaled gradients를 역으로 unscale한 값으로 weight를 업데이트한다.
@tf.function def train_step(x, y): with tf.GradientTape() as tape: predictions = model(x) loss = loss_object(y, predictions) scaled_loss = optimizer.get_scaled_loss(loss) scaled_gradients = tape.gradient(scaled_loss, model.trainable_variables) gradients = optimizer.get_unscaled_gradients(scaled_gradients) optimizer.apply_gradients(zip(gradients, model.trainable_variables)) return loss
model.compile(), model.fit() 사용 시에는 2번까지 진행하면 default로 auto scaling을 진행한다.
참고자료
[부동소수점] https://ai-study.tistory.com/37
[mixed precision] https://hoya012.github.io/blog/Mixed-Precision-Training/
[tensorflow 공식사용법] https://www.tensorflow.org/guide/mixed_precision?hl=ko
[논문] https://arxiv.org/pdf/1710.03740