
티스토리 뷰
안녕하세요 오늘은 파이썬으로 크롤링하는 법을 알아보겠습니다.
크롤링이란 인터넷에 있는 다양한 정보들을 필요한 것들만 뽑아 가져오는 것을 말합니다.
오늘 진행할 웹크롤링을 하기 위해선 파이썬과 HTML의 기초를 알고 계셔야 합니다.
예시로 네이버 영화 순위 페이지에서 영화 목록과 평점을 가져오는 실습을 해보겠습니다.
https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200324
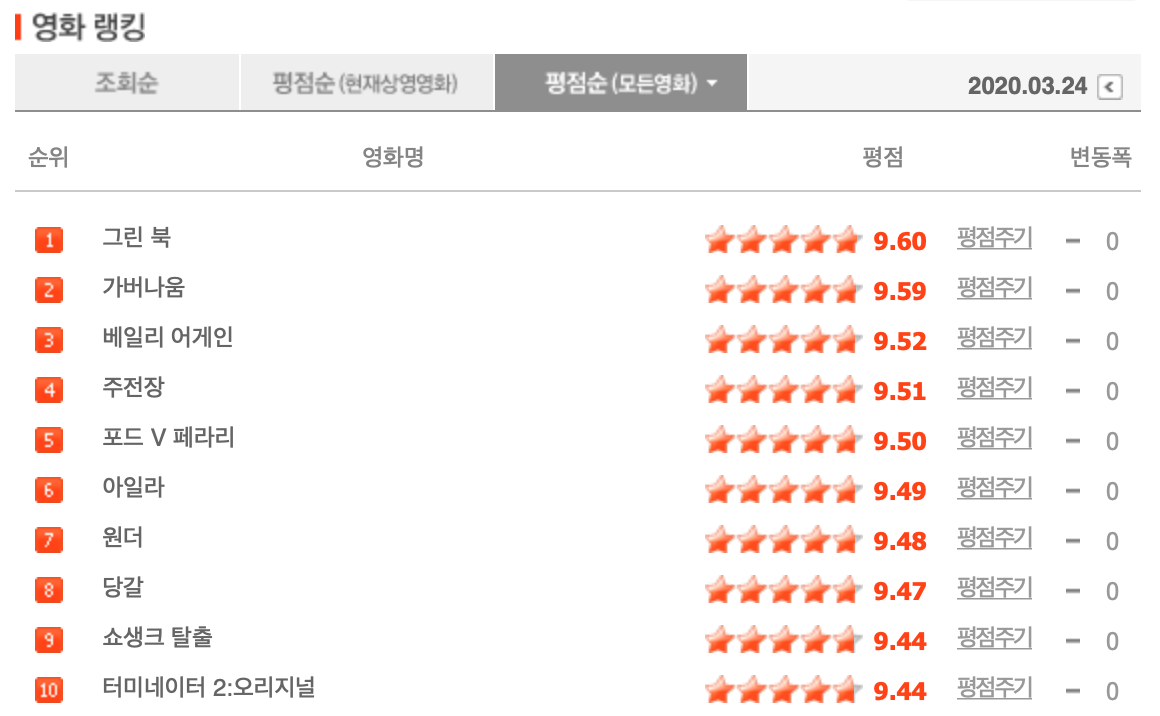
위의 링크는 네이버 영화 순위 페이지인데요, 현재까지 개봉한 모든 영화를 평점 기준으로 나열한 리스트입니다.
한 페이지에 50개씩 영화 리스트와 각 영화의 평점이 있습니다.
이 페이지에서 마우스 오른쪽 버튼을 클릭하여 페이지 소스 보기를 해줍니다. (크롬 사용 권장)
그러면 아래와 같이 html 소스가 있습니다. 그중 아래와 같이 영화 이름과 평점의 정보를 담고 있는 HTML 태그를 확인합니다.
영화 이름은 td태그, title이라는 class, 그 안에는 div태그, tit5라는 class로 되어있습니다.
평점은 td태그, point라는 class로 되어있습니다.

여기까지 확인하였으면 이제 크롤링에 필요한 파이썬 라이브러리 beautifulsoup를 아래와 설치해줍니다.
pip install beautifulsoup4설치하였으면 python 소스로 확인해 보겠습니다.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import ssl
context = ssl._create_unverified_context()
url = "https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200324&page=1"
page = urlopen(url, context=context)
document = page.read()
page.close()
soup = BeautifulSoup(document, "html.parser")
movie_list = soup.find_all("td", class_="title")
point_list = soup.find_all("td", class_="point")
movies = []
for movie, point in zip(movie_list, point_list):
row = [movie.get_text()[2:-2], point.get_text()]
movies.append(row)위의 BeautifulSoup를 통해서 soup라는 변수에 html정보가 담깁니다.
soup.find_all('태그명', class_='class명')을 호출하면 해당 태그와 class명을 가진 모든 태그를 가져옵니다.
위에서 살펴본 것처럼 td태그와 각 class명을 입력하여 영화 목록과, 평점 목록을 가져옵니다.
이제 영화, 평점 목록들을 movies라는 배열에 한쌍씩 append 해줍니다.
그럼 movies라는 배열에는 영화이름과 평점이 담긴 2차원 배열이 됩니다.

이렇게 원하는 페이지에서 beautifulsoup 라이브러리를 통해서 원하는 정보를 크롤링할 수 있습니다.
'Python' 카테고리의 다른 글
| [Python] Selenium을 이용하여 인터넷 사용하기(크롤링, 로그인 등) (0) | 2020.09.12 |
|---|---|
| [Python] Tistory API 사용하는 방법(Access Token 받기) (2) | 2020.08.22 |
| [Python] 파이썬으로 메일보내기 (파일첨부) (6) | 2020.03.23 |
| [Python] logging 사용법 (로그 출력) (2) | 2020.01.15 |
| [Python] 폴더 또는 경로(디렉토리) 생성(mkdir, makedirs 차이) (0) | 2020.01.14 |
- Total
- Today
- Yesterday