
Sweep
- 다양한 하이퍼파라미터를 자동으로 학습하여 시각적인 그래프로 보여준다.
- 하이퍼파라미터를 튜닝하는 모든 알고리즘은 open source로 공개되어있다.

Sweep 세팅
설치
pip3 install wandb
wandb loginsweep config 설정
- yaml 파일로 탐색할 hyperparameters를 지정한다.
- metric name으로 지정한(아래 예시에서는 validation_loss)는 반드시 학습 코드 내에
wandb.log({’validation_loss’:val_loss})형태로 로그되어야 한다.
# sweep_sample.yaml
program: train.py
method: bayes
metric:
name: validation_loss
goal: minimize
parameters:
learning_rate:
min: 0.0001
max: 0.1
optimizer:
values: ["adam", "sgd"]sweep initialize
- 아래 명령어를 통해서 initailize 한다.
- 명령어를 실행하면 프로젝트 이름과 entity이름이 포함된 sweep id가 출력된다. 이를 복사해둔다.
wandb sweep sweep.yamlsweep agent 실행
- 위에서 복사한 값으로 agent를 실행한다.
wandb agent <USERNAME/PROJECTNAME/SWEEPID>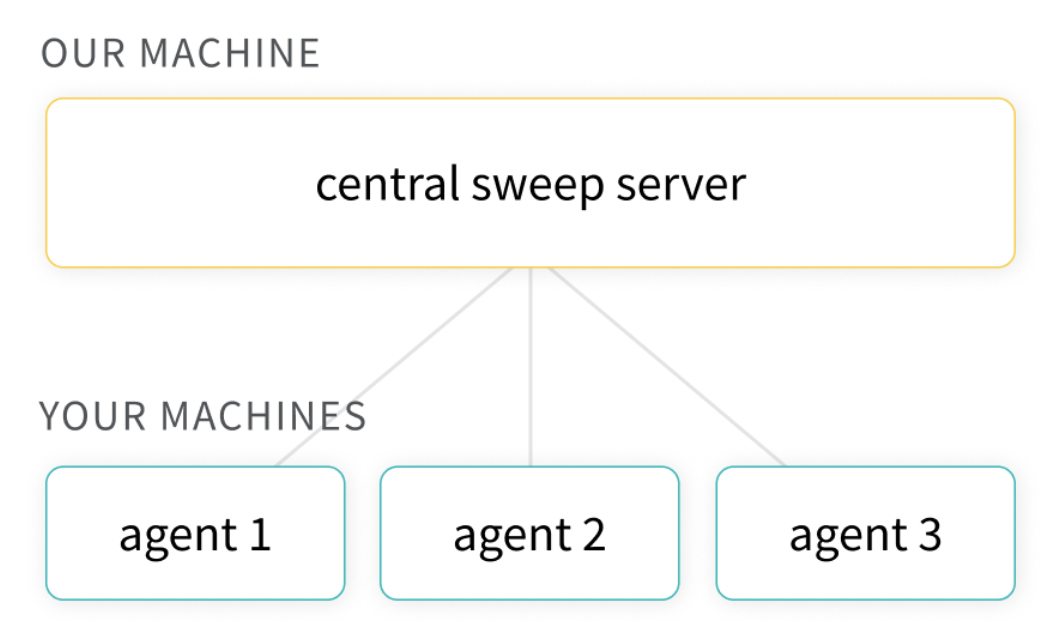
sweep 종료하기
- sweep이 끝까지 모두 진행되면 자동적으로 종료된다.
- 중간에 멈추고 싶으면
Ctrl+c를 눌러 프로세스를 종료시킨다.
Sweep 상세 설정
python script로도 sweep을 설정할 수 있지만, yaml파일로 실험 관리하는게 편리해 보인다.
| Key | 설명 |
|---|---|
| program (required) | 실행할 python 파일 이름 |
| name | sweep 실행할 이름 |
| description | sweep에 대한 설명 |
| project | sweep 실행할 프로젝트명 |
| entity | sweep 실행하는 entity명 |
| metric | - 최적화할 metric 지정 (탐색 전략과 early stopping 방법에 사용)
name: optimize할 metric의 이름 지정
goal: minimize(default), maxmize
target: 해당 metric의 목표값으로 이 값을 도달하면 더 이상 실험하지 않음 |
| method (required) | - 하이퍼파라미터 탐색 전략 grid: 가능한 모든 조합 탐색 random: 파라미터들을 랜덤하게 선택 bayes: 좀 더 확인 |
| parameters (required) | - 탐색할 파라미터를 지정
values: 탐색할 값의 리스트
value: single 값으로 탐색하지 않음
distribution(str): random, bayes 방법을 사용할 때 categorical, int_uniform, uniform, constant 등의 다양한 파라미터 선택 방법
probabilities: random 방법, values를 사용할 때 각 요소를 탐색할 확률리스트
min, max(int, float):
mu(float): normal, lognormal을 사용할 때의 평균
sigma(float): normal, lognormal을 사용할 때의 표준편차
q(float): Quantization step size for quantized hyperparameters
parameters: 다른 파라미터의 내부 값으로 적을 때의 파라미터 |
| early_terminate | - early stopping 방법 지정
type: stopping 알고리즘 지정 e.g. hyperband |
| command | - python 파일을 실행할 때 지정할 argument |
- 예제
# sample.yaml
program: train.py
method: bayes
name: test_sweep
description: test sweep method
project: my_sweep_test
entity: username_or_teamname
metric:
name: validation_loss
goal: minimize
parameters:
learning_rate:
min: 0.0001
max: 0.1
optimizer:
values: ["adam", "sgd"]
epochs:
value: 5
parameter1:
distribution: normal
mu: 100
sigma: 10
early_terminate:
type: hyperband
min_iter: 3기타 사용법
- random, bayesian 탐색은 직접 프로세스를 끄기전까지 종료되지 않고 계속 탐색한다.
- 따라서 metric의 값에 따라 종료 조건을 지정하거나 직접 학습 횟수를 제한해줄 수 있다.
wandb agent --count [LIMIT_NUM] [SWEEPID]- sweep은 wandb의 entity와 project에 연결되어서 학습한다. 따라서 실행 시 지정하거나 yaml파일에 지정해 줄 수 있다.
- 방법1
wandb sweep --entity geoff --project capsules- 방법2
# inside of sweep_config.yaml entity: username_or_teamname project: project_name
- multi-gpu에서 sweep을 사용할 수 있다.
- sweep_id는 wandb sweep [yaml파일] 명령어를 통해 알 수 있다.
CUDA_VISIBLE_DEVICES=0 wandb agent sweep_id
CUDA_VISIBLE_DEVICES=1 wandb agent sweep_id- pprint로 config를 보기좋게 출력, 확인할 수 있다.
import pprint
pprint.pprint(sweep_config)sweep results 시각화 그래프
- hyper parameter의 값에 따라 loss에 반영되는 그래프를 그려준다.
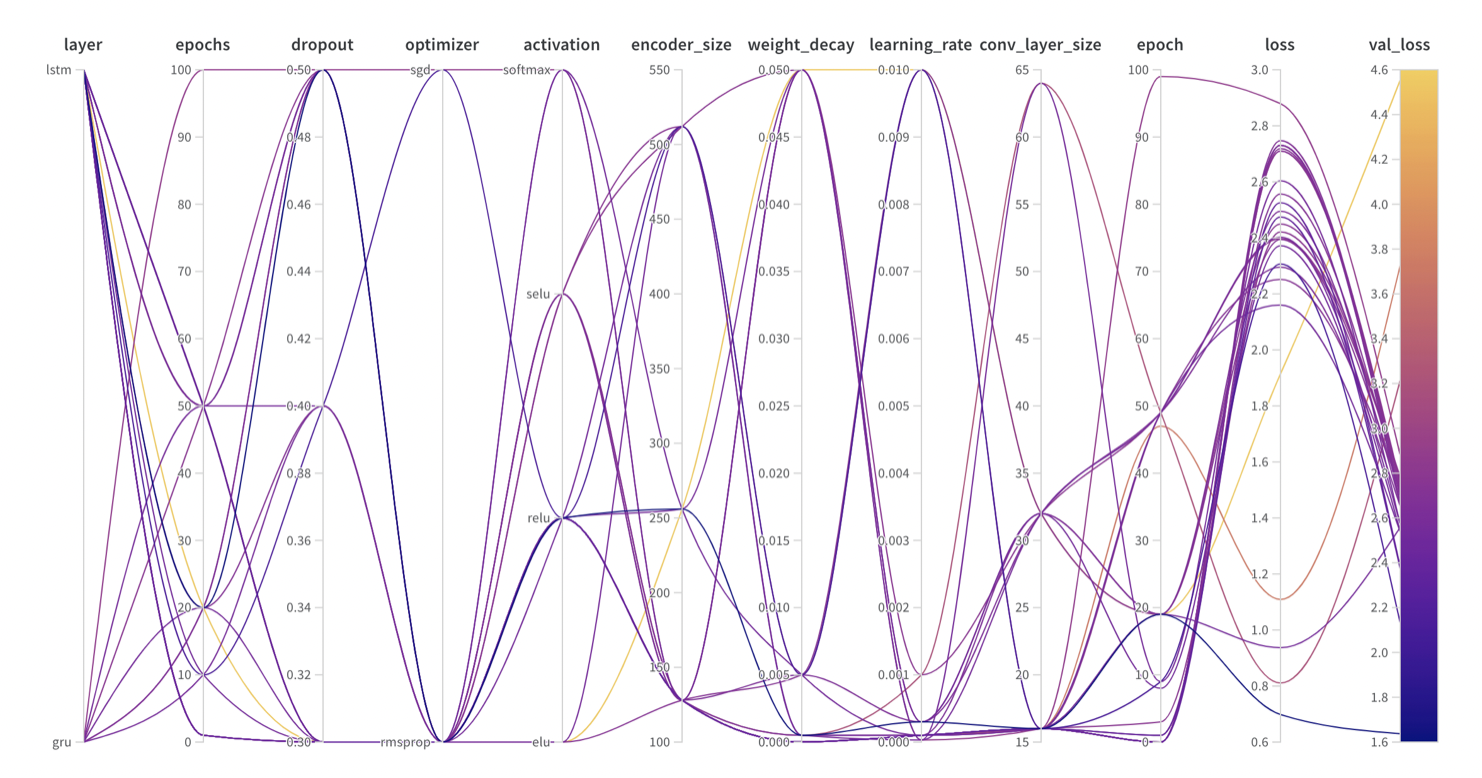
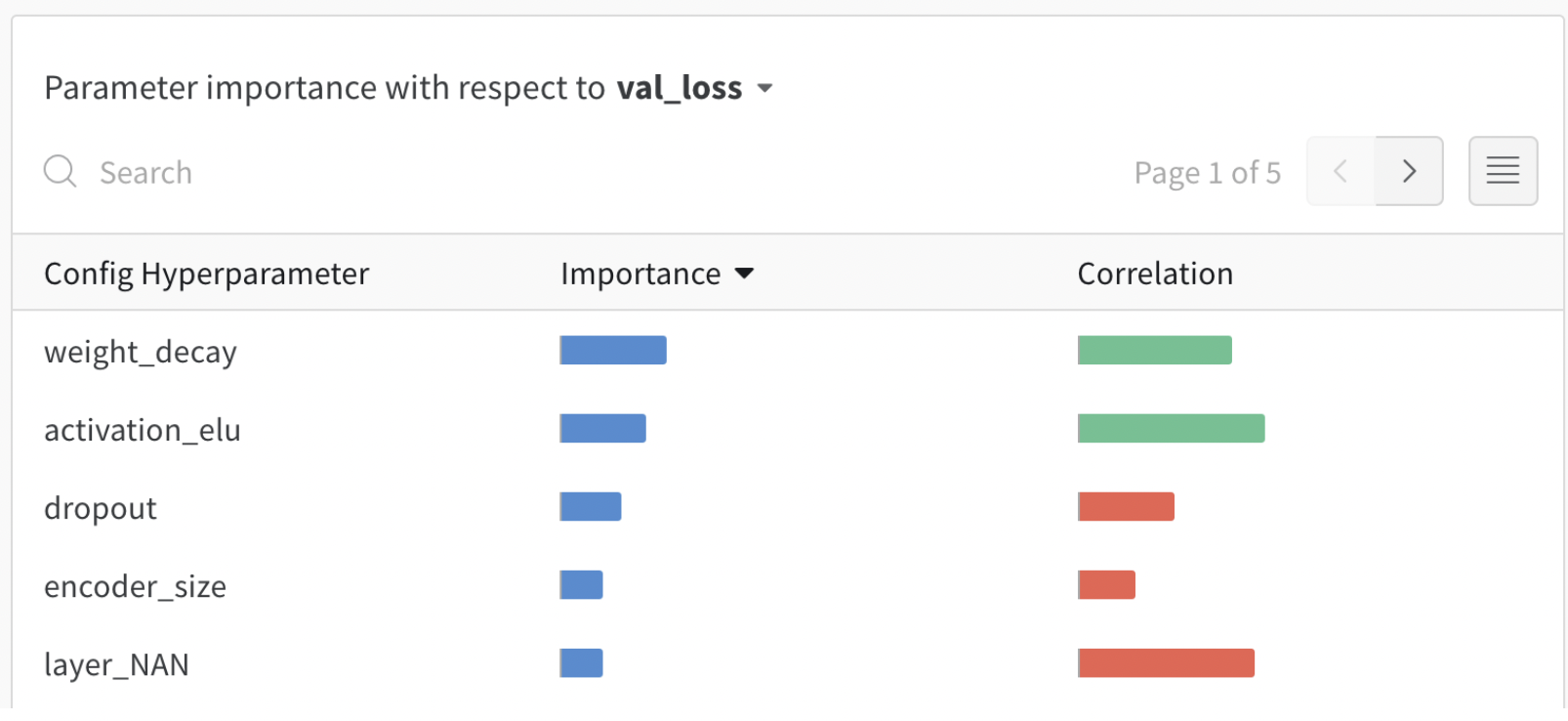
- 각 hyper parameter와 loss 사이의 importance(from Random Forest Model), correlation(from Linear Model)을 각각 보여준다.
F-Mnist로 학습
Pytorch에서 제공하는 Fashion-Mnist 학습 예제 코드를 활용해서 sweep을 적용해 보았다.
학습을 하는 python 파일의 이름은 train_widh_wandb.py이다.
- 아래와 같은 sweep 설정 파일이 담긴 yaml 파일을 생성한다.
- 학습의 목표는 test_loss가 제일 낮은 것을 목표로 하고, lr은 2가지, bs는 3가지, epoch은 고정이기 때문에 학습할 수 있는 경우의 수는 6가지이다.
# sweep.yaml
program: train_with_wandb.py
method: grid
name: fmnist-sweep
project: f-mnist
entity: jmjeon94
metric:
name: test_loss
goal: minimize
parameters:
learning_rate:
values: [ 0.001, 0.01 ]
batch_size:
values: [ 32, 64 , 128 ]
epochs:
value: 5학습 코드는 지난번의 wandb 사용법 게시물에서 사용했던 학습 코드를 그대로 사용한다.
신기하게도 코드 내에 있는 wandb config에 지정된 값으로 학습되는게 아니라, 해당 config 값이 sweep 설정에 의해 자동적으로 튜닝하셔 학습하게 된다.
wandb를 적용한 pytorch기반 F-MNIST 학습 코드 보기
[MLOps] WandB 사용방법 (pytorch에서 사용하기)Weights & Biases란? wandb는 MLOps 플랫폼으로 머신러닝, 딥러닝을 학습하는데 필요한 다양한 기능들을 제공한다. 대표적으로 아래의 기능등을 갖추고 있다. 실험관리 하이퍼파라미터 튜닝 데이터, 모델 버저닝..https://minimin2.tistory.com/186

import torch from torch import nn from torch.utils.data import DataLoader from torchvision import datasets from torchvision.transforms import ToTensor import wandb # init wandb settings run = wandb.init(project="f-mnist") cfg = { "learning_rate": 1e-3, "epochs": 5, "batch_size": 64 } wandb.config.update(cfg) # Download training data from open datasets. training_data = datasets.FashionMNIST( root="data", train=True, download=True, transform=ToTensor(), ) # Download test data from open datasets. test_data = datasets.FashionMNIST( root="data", train=False, download=True, transform=ToTensor(), ) # Create data loaders. train_dataloader = DataLoader(training_data, batch_size=cfg['batch_size']) test_dataloader = DataLoader(test_data, batch_size=cfg['batch_size']) for X, y in test_dataloader: print(f"Shape of X [N, C, H, W]: {X.shape}") print(f"Shape of y: {y.shape} {y.dtype}") break # Get cpu or gpu device for training. device = "cuda" if torch.cuda.is_available() else "cpu" print(f"Using {device} device") # Define model class NeuralNetwork(nn.Module): def __init__(self): super(NeuralNetwork, self).__init__() self.flatten = nn.Flatten() self.linear_relu_stack = nn.Sequential( nn.Linear(28 * 28, 512), nn.ReLU(), nn.Linear(512, 512), nn.ReLU(), nn.Linear(512, 10) ) def forward(self, x): x = self.flatten(x) logits = self.linear_relu_stack(x) return logits model = NeuralNetwork().to(device) print(model) loss_fn = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=cfg['learning_rate']) def train(dataloader, model, loss_fn, optimizer, epoch): size = len(dataloader.dataset) model.train() total_loss = 0 for batch, (X, y) in enumerate(dataloader): X, y = X.to(device), y.to(device) # Compute prediction error pred = model(X) loss = loss_fn(pred, y) total_loss += loss.item() # Backpropagation optimizer.zero_grad() loss.backward() optimizer.step() if batch % 100 == 0: loss, current = loss.item(), batch * len(X) print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]") wandb.log({"train_loss": total_loss / len(dataloader)}, step=epoch) def test(dataloader, model, loss_fn, epoch): size = len(dataloader.dataset) num_batches = len(dataloader) model.eval() test_loss, correct = 0, 0 with torch.no_grad(): for X, y in dataloader: X, y = X.to(device), y.to(device) pred = model(X) test_loss += loss_fn(pred, y).item() correct += (pred.argmax(1) == y).type(torch.float).sum().item() test_loss /= num_batches correct /= size print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n") wandb.log({"test_loss": test_loss, "test_acc": correct}, step=epoch) epochs = cfg['epochs'] for t in range(epochs): print(f"Epoch {t+1}\n-------------------------------") train(train_dataloader, model, loss_fn, optimizer, t) test(test_dataloader, model, loss_fn, t) print("Done!") torch.save(model.state_dict(), "model.pth") print("Saved PyTorch Model State to model.pth") model = NeuralNetwork() model.load_state_dict(torch.load("model.pth")) classes = [ "T-shirt/top", "Trouser", "Pullover", "Dress", "Coat", "Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot", ] model.eval() x, y = test_data[0][0], test_data[0][1] with torch.no_grad(): pred = model(x) predicted, actual = classes[pred[0].argmax(0)], classes[y] print(f'Predicted: "{predicted}", Actual: "{actual}"')
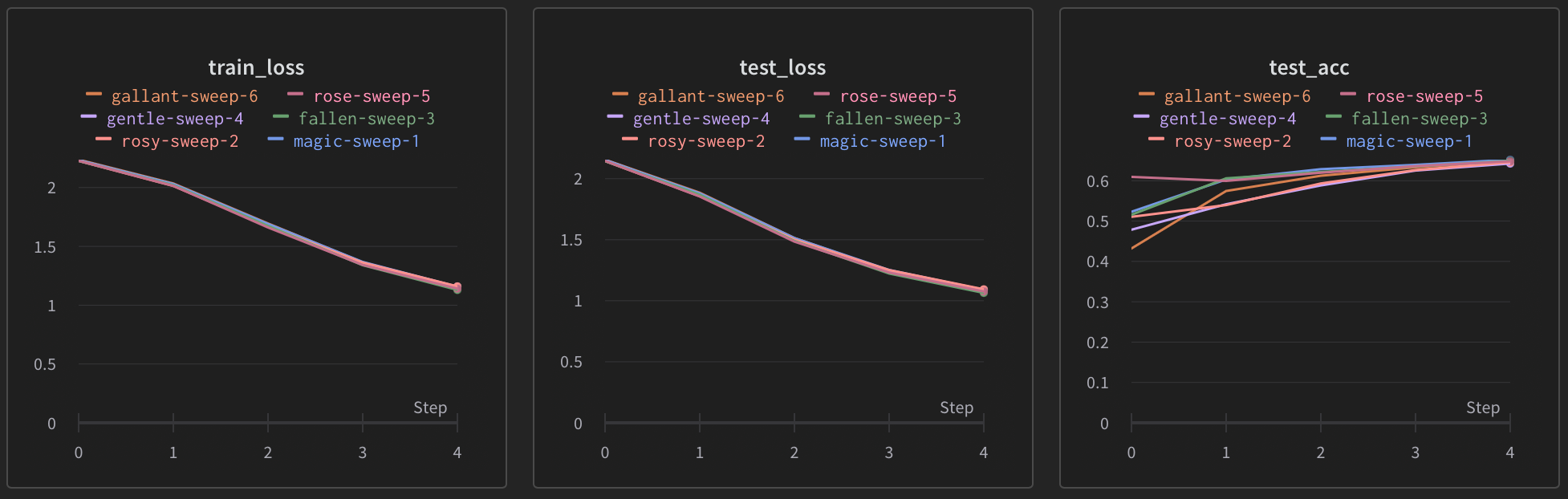
학습 결과
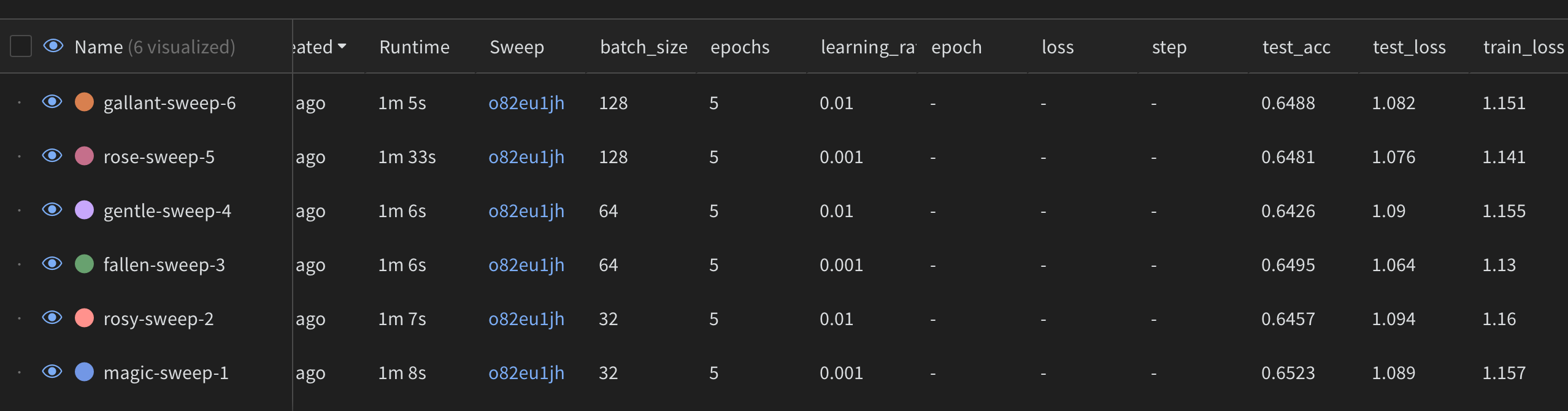
- wandb UI 에서 학습 결과를 확인할 수 있다. 경우의 수가 6가지이기 때문에 총 6번의 학습 그래프가 그려진다. wandb.log()함수로 log를 남긴 train_loss, test_loss, test_acc가 모두 기록된다.
- 두번째 테이블을 보면 각각 6번 학습의 파라미터를 확인할 수 있고, 그렇게 학습된 결과의 최종 best metric도 한 눈에 확인할 수 있다.
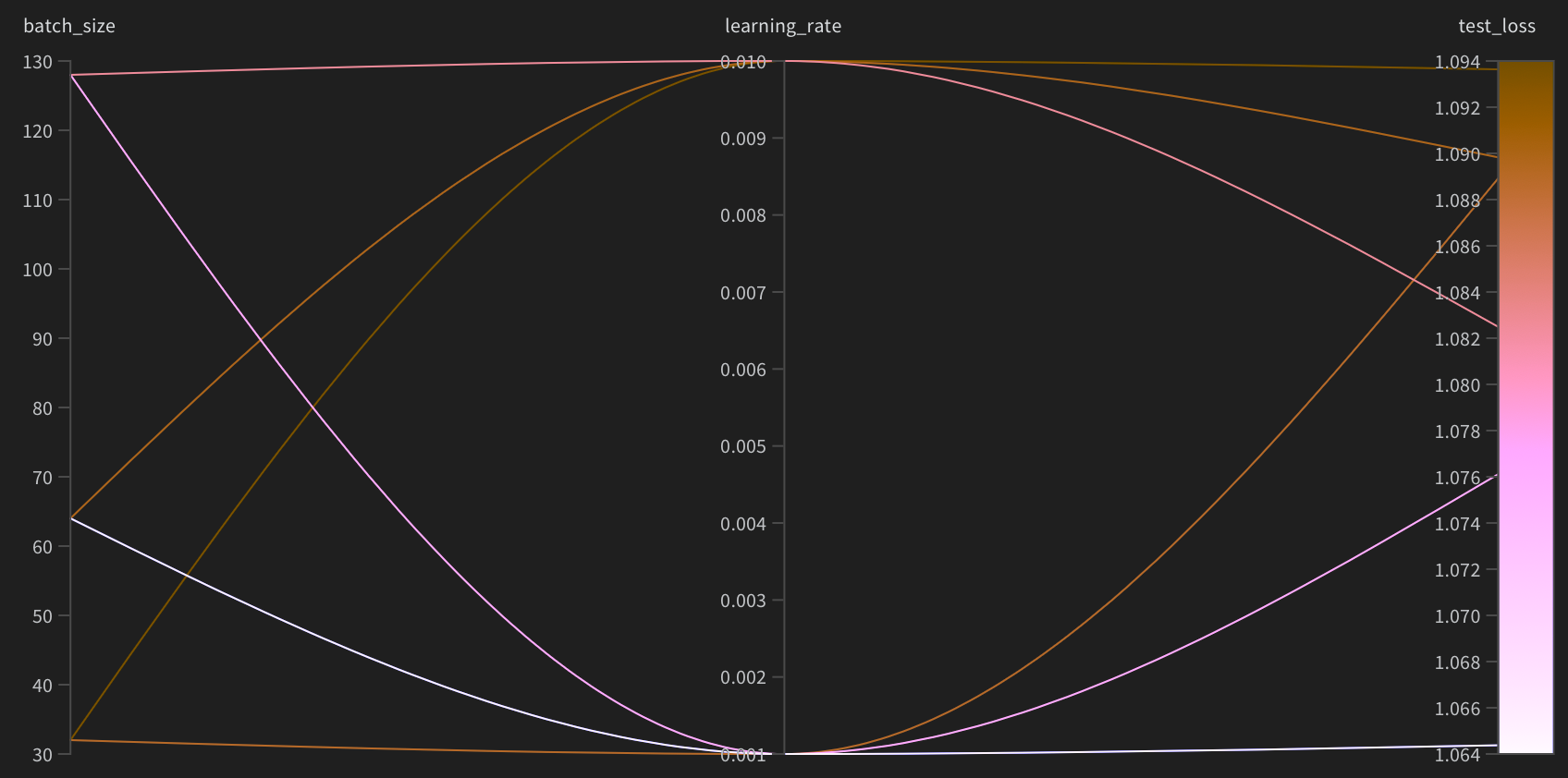
- 3번째 그래프를 보면 각각의 파라미터로 학습했을 때, test_loss가 어떻게 되는지를 그려주는 그래프를 보여준다. 이 그래프를 보면 최종적으로 어떤 파라미터로 학습할때가 최적인지 한 눈에 알 수 있다.
Uploaded by N2T